이 글은 인프런 Spring Cloud로 개발하는 마이크로서비스 애플리케이션(MSA) 강의를 듣고 쓴 글입니다.
Spring Cloud로 개발하는 마이크로서비스 애플리케이션(MSA) - 인프런 | 강의
Spring framework의 Spring Cloud 제품군을 이용하여 마이크로서비스 애플리케이션을 개발해 보는 과정입니다. Cloud Native Application으로써의 Spring Cloud를 어떻게 사용하는지, 구성을 어떻게 하는지에 대해
www.inflearn.com
섹션 11, 12는 Apache Kafka에 대해 다룰 것이다. Apache Kafka 는 공부해야 할 양이 너무 많아서 두 개의 섹션에 걸쳐 공부한다.
Apache Kafka 란?
Apache Software Foundation의 Scalar 언어로 된 오픈 소스 메시지 브로커 프로젝트이다. 메시지 브로커란 메시지를 전달할 때 사용되는 서버라고 생각하면 된다.
링크드인에서 개발했고, 2011년에 오픈 소스화 되었다.
실시간 데이터 피드를 관리하기 위해 통일된 높은 처리량을 제공해주고 낮은 지연 시간을 지닌 플랫폼을 제공해준다.
Apple, Netflix에서 데이터를 전달하기 위해 Kafka 메시지 브로커를 사용하고 있다.
이는 End-to-End 연결 방식의 아키텍처와 대조적이다. 모든 서비스가 그물망처럼 얽혀있으면 복잡성이 증가하고 확장도 어렵다. Apache Kafka 는 모든 시스템으로 데이터를 실시간으로 전송하여 처리할 수 있는 시스템이다. 데이터가 많아지더라도 확장이 용이하다.
Kafka의 특징
- Producer/Consumer가 분리되어 있다.
- 하나의 메시지를 여러 Consumer에게 허용할 수 있다.
- 높은 처리량을 위해 메시지를 최적화해서 보관한다.
- 클러스터링을 통해 Scale-out이 가능하다.
- 스트리밍 서비스에도 이용 가능하고, SQL 문법을 지원하는 등 다양한 eco-system을 가지고 있다. Kafka Client, Kafka Connect 등이 있다.
Kafka의 구조
Kafka 애플리케이션 서버는 Broker 들로 이루어져 있다. 보통 3대 이상의 Broker Cluster로 구성하는 것을 권장한다. 각 브로커끼리의 상황 공유, 문제가 생겼을 때 대처 등을 위해 코디네이터(coordinator)를 사용하는데, 그 중 대표적인 Apache Zookeeper를 사용한다.
Zookeeper는 Broker ID, Controller ID 등 메타데이터를 저장하고, 문제 상황 발생 시 대처하는 등의 역할을 한다.
브로커들 중 1대는 Controller, 즉 리더의 기능을 수행한다. Controller는 각 브로커에게 담당 파티션 할당을 수행하고 다른 브로커들을 모니터링한다. Controller에게 문제가 생길 경우 Zookeeper가 Controller를 교체하는 등의 조치를 취한다.
Apache Kafka 설치
Apache Kafka
Apache Kafka: A Distributed Streaming Platform.
kafka.apache.org
이 곳에서 다운로드하면 된다. 운영체제에 상관 없이 .tgz 확장자로 제공되고 있고, 다운로드받은 후에 다음과 같은 명령어로 압축해제하면 된다. (다른 압축 해제 프로그램으로도 가능하다. 사실 mac 에서 그냥 더블클릭해도 알아서 풀린다.)
tar xvf Kafka_2.13-3.5.1.tgz #버전 명은 각자 알아서압축 해제된 폴더들을 보자. 2가지 폴더가 중요하다.
우선, config 폴더에는 server.properties 파일과 zookeeper.properties 파일이 있다. 각각 Kafka 서버와 Zookeeper에 쓰이는 설정 파일이다. 다른 용도의 설정 파일도 많다.
그리고 bin 폴더에는 kafka와 Zookeeper등의 제어에 쓰이는 .sh 파일들이 있다. 윈도우는 이 안에 windows 폴더에 .bat 파일로 실행하면 된다.
Apache Kafka 사용
이제 직접 Kafka를 사용해보자. 우리는 일단 각각 1대의 Kafka와 Zookeeper 를 사용할 것이다. 실무에서는 각각 3대 정도 이상을 쓰면 안정적이다.
Producer/Consumer (Kafka Client)
Kafka Client를 활용해 테스트해본다. kafka client는 java library 가 있어서 의존성만 추가해줘도 된다.
https://mvnrepository.com/artifact/org.apache.kafka/kafka-client
또한, Producer, Consumer 등의 Kafka 관련 API도 제공되고, C/C++, Node.js 같은 언어에 대한 3rd party library 도 존재한다.
직접 Kafka 서버와 Zookeeper를 기동해서 사용해보자. 터미널 창은 Zookeeper 와 Kafka 서버 구동에 하나씩, Producer와 Consumer 에 하나씩, 총 4개는 켜놓고 있어야 한다. 모든 명령은 Kafka 설치 경로에서 이루어진다.
우선 Zookeeper를 구동한다. 첫 터미널 창에서 다음과 같은 명령어를 실행한다.
./bin/zookeeper-server-start.sh ./config/zookeeper.propertiesZookeeper가 실행된다. 포트번호는 기본값이 2181이다.
이제 Kafka 서버를 구동한다. 새로운 터미널 창에 다음과 같은 명령어를 실행한다.
./bin/kafka-server-start.sh ./config/server.propertiesKafka 서버가 실행된다. 포트번호는 기본값이 9092이다.
만약, 뒤에서 Client가 Kafka 서버에 접근하지 못하고 Timeout 이 된다면, localhost:9092에 접근하지 못하는 것이다. 설정파일을 수정해야 한다. 자세한 내용은 다음을 참고하자. https://wildeveloperetrain.tistory.com/219
Kafka TimeoutException 해결 방법 org.apache.kafka.common.errors.TimeoutException: Call(callName=listTopics ...)
kafka 서버 기동을 위해 'zookeeper 서버 기동' -> 'kafka 서버 기동' -> 'kafka 서버에 요청'을 하는 중 'TimeoutException'이 발생하여 해결한 내용입니다. (사용된 kafka 버전은 kafka_2.13-2.7.0 버전입니다.) Zookeeper
wildeveloperetrain.tistory.com
이제 Kafka 서버에 Topic을 만들고, Producer와 Consumer의 메시지 전달 과정을 보자.
Topic 관련 명령어
새로운 터미널 창에 Topic 관련된 명령어를 실행해보자. 다음과 같은 명령어들이 있다.
./bin/kafka-topics.sh --bootstrap-server localhost:9092 --list # Topic 리스트 조회
./bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic quickstart-events --partitions 1 # Topic 생성
./bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic quickstart-events # Topic 상세 조회우선 리스트 조회 명령어를 입력하면 아무것도 안 뜰 것이다. Topic을 직접 만들어보자.
Topic 생성 명령어를 쳐보자. 이름은 quickstart-events로 만든 것이고, partitions 는 1개로 한 것이다. partitions 는 나중에 설명하겠다.
이제 리스트 조회를 하면 현재 생성된 Topic이 나올 것이다. Topic 의 partition 등 상세 조회를 하고 싶으면 상세 조회를 해보자.
이제 Topic을 만들었으니 Producer가 되어 메시지를 전달해보자. 다음과 같은 명령어를 실행한다.
./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic quickstart-events이제 입력할 수 있는 커서로 바뀔 것이다.
새로운 창에서 Consumer를 만들어보자. 다음과 같은 명령어를 실행한다.
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic quickstart-events --from-beginningquickstart-events 라는 Topic을 처음 메시지부터 (--from-beginning) 구독하는 Consumer를 만든다. 이제 입력할 수 없는 커서로 바뀔 것이다.
설정은 모두 끝났다. Producer 창에 돌아가 하고 싶은 말을 적고 엔터를 누르면 곧바로 Consumer에게 전달되는 것을 볼 수 있다.


이렇게 콘솔에서 직접 전달하는 것이 console producer/consumer 이다.
위에서 설명했듯이 Consumer는 여럿일 수 있다. Consumer를 하나 더 만들어보자. 위와 똑같은 명령어를 입력하면된다.
그러면 --from-beginning 옵션때문에 맨 처음 메시지부터 그대로 출력되는 것을 볼 수 있다.
Kafka Connect 란?
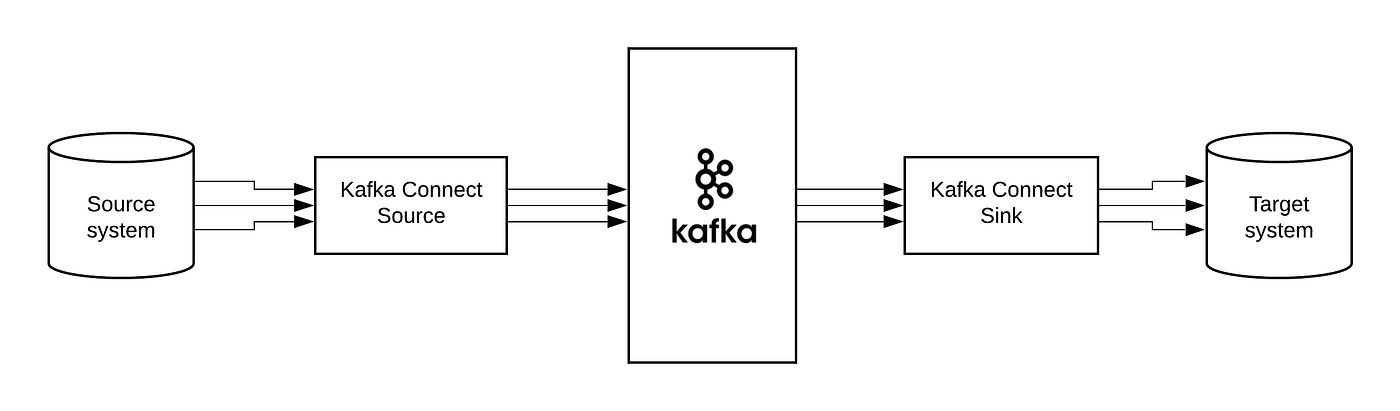
이전에는 코드 등을 이용해서 각 서비스들끼리 Client가 되어 Prod/Cons 구조로 메시지를 공유했다. 이제 Connect 를 통해 Source System에서부터 Data를 Import 해 Target System으로 Data를 Export 할 수 있다.
즉, 코드 없이 Configuration 만으로 데이터를 이동할 수 있다.
Standalone 혹은 Distribution 모드로 작동할 수 있다. 데이터는 RESTful API 를 통해 Stream 혹은 Batch 형태로 전송할 수 있고, 커스텀 Connector를 통해 다양한 Plugin 을 제공한다.
우리는 Order Service 에 MySQL을 연동시켜 Connect 동작을 시켜볼 것이다. MySQL 설치는 구글링을 통해서!! 하고 연동부터 해보자.
Order Service에 mysql 연동을 위해 다음과 같은 의존성을 추가한다. (이 부분에서 기존에는 Order Service가 Java11 & Spring Boot 2.7.2 였는데, H2와 MySQL 호환에 문제가 생겨 Java17 & Spring Boot 3.1.2로 마이그레이션 하였다. 이 마이그레이션에서 가장 조심해야 할 것은 javax -> jakarta 와 스프링 시큐리티 이다.)
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
</dependency>또한, MySQL 을 h2 console로 접속해서 데이터를 확인할 것이다. h2 console에서는 h2 뿐만 아니라 다양한 데이터베이스에 접속할 수 있다. Order Service를 실행하고 h2-console로 접속해보자.
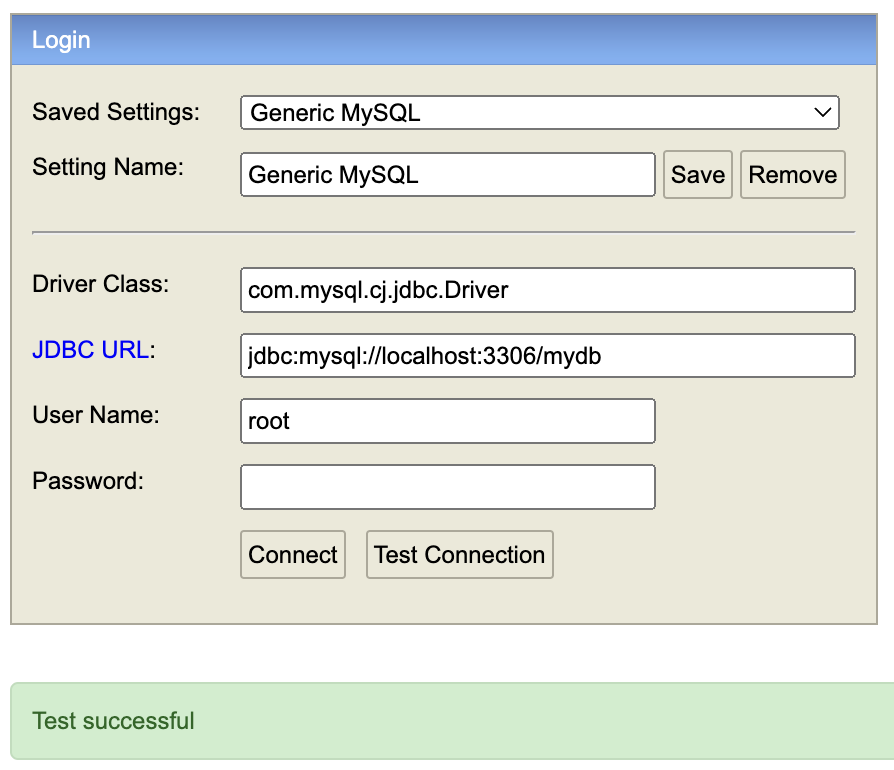
- Settings 를 Generic MySQL 로 바꾼다.
- Driver Class 는 중간에 cj를 넣어야 한다. com.mysql.jdbc.Driver 는 Deprecated 되었다.
- JDBC URL의 끝에는 미리 만든 데이터베이스를 넣는다. 터미널 창에서 mydb라는 데이터베이스를 만들고 오자.
이제 콘솔창으로 들어가 다음과 같은 테이블을 하나 만들어놓자.
CREATE TABLE users(
id INT AUTO_INCREMENT PRIMARY KEY,
user_id VARCHAR(20),
pwd VARCHAR(20),
name VARCHAR(20),
created_at DATETIME DEFAULT NOW()
);Kafka Connect 설치
이제 Kafka Connect를 직접 설치해보자. 상당히 어지러웠으니 잘 해야 한다...
우선, Kafka Connect 를 직접 설치하자. 아래의 URL에 접속하면 바로 다운로드 된다. 최신 버전이 7.4라고 떠서 7.4버전을 설치했다.
http://packages.confluent.io/archive/7.4/confluent-community-7.4.0.tar.gz
원하는 경로에 두자. 아까 깔았던 Kafka 서버와 같은 곳에 두는 게 좋을 것이다. 압축을 풀고 아래와 같은 명령어로 실행해보자. Zookeeper와 Kafka는 실행된 상태여야 한다.
./bin/connect-distributed ./etc/Kafka/connect-distributed.propertiesconnect-distributed 를 실행하는 데에 필요한 설정 파일로 /etc 의 connect-distributed.properties 를 사용한 것이다.
이 때, 위에서 했던 Topic 목록 확인 명령어를 사용하면 다음과 같은 Topic 들이 생겨나있을 것이다.

Connect 에 필요한 Topic들을 자동으로 생성한 것이다.
또 하나만 설치해보자. Connector 가 MySQL와 연동되어야 하기 때문에 JDBC Connector 가 추가로 필요하다. 다음 URL에 접속해 다운로드 버튼을 누르자.
https://www.confluent.io/hub/confluentinc/kafka-connect-jdbc
JDBC Connector (Source and Sink)
Confluent, founded by the original creators of Apache Kafka®, delivers a complete execution of Kafka for the Enterprise, to help you run your business in real-time.
www.confluent.io
아까와 같은 경로에 압축을 해제하자.
2가지만 더 하면 설정이 끝난다. plugin.path 수정과 mysql 라이브러리 복사이다.
1. 설치한 Connect의 설정파일에 가서 한 가지를 수정해야 한다. confluent-7.4.0/etc/kafka/connect-distributed.properties 파일을 열어보자 (VS Code) 맨 밑에 plugin.path 값이 있을 것이다. 여기에 원래 값 대신 조금 전에 다운로드받은 파일의 경로를 지정할 것이다. 아래와 같이 써주자.
plugin.path=/Users/사용자/Desktop/MSA/Kafka/confluentinc-kafka-connect-jdbc-10.7.4/lib
2. Connector에서 MySQL 라이브러리를 사용할 수 있게 jar 파일을 설정해주자. 그런데 우리는 이걸 의존성에 추가한 적이 있다. 즉 우리 컴퓨터 어딘가에는 이 jar 파일이 있다는 것이다. 아래 경로에 있다.
/Users/사용자/.m2/repository/com/mysql/mysql-connector-j/8.0.33 # 8.0.33은 버전여기 있는 파일 중 jar 파일을 Connector 가 쓸 수 있도록 Connector의 영역에 복사해 줄 것이다. 아래와 같이 입력하자.
cp ./mysql-connector-j-8.0.33.jar /Users/사용자/Desktop/MSA/Kafka/confluent-7.4.0/share/java/kafka이제 저 경로에 가서 잘 복사되었는지만 확인하면 설정은 끝!
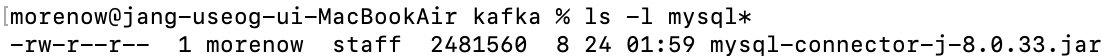
Kafka Connect 사용
Kafka Source Connect 사용
이제 MySQL에서 변경이 일어나면 Kafka Cluster에게 전해주는 Source Connect를 기동하고 사용해보자.
다음 명령어로 Source Connect를 기동한다.
./bin/connect-distributed ./etc/kafka/connect-distributed.properties그리고 내 mydb 안에 있는 users 데이터베이스에서 변경이 일어나면 알아차리는 Topic을 생성하자. RESTful API 로 할 수 있어서 Postman을 활용해 등록하면 된다.
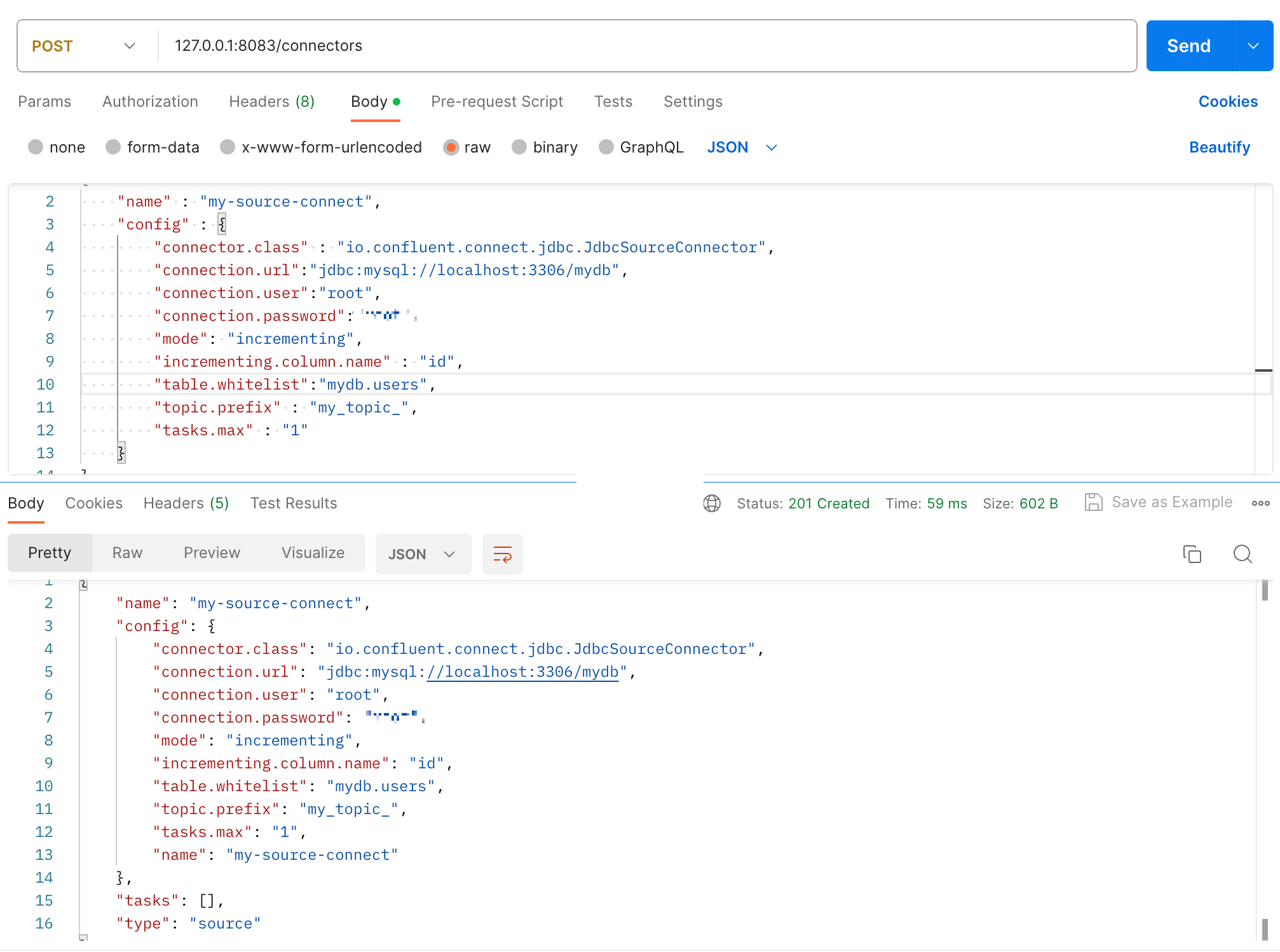
- 여기서 Topic은 prefix 이름에 실제 이름를 더한 것이다. 이 경우 my_topic_users 가 된다.
- topic.whitelist 에는 우리의 경우 테이블 이름을 써야 하는데, 그냥 user라고 쓰면 다른 데이터베이스의 테이블과 구분하지 못해 mydb.users와 같이 데이터베이스.테이블명 형식으로 써야 한다.
https://www.inflearn.com/questions/618181/source-connector-%EC%98%A4%EB%A5%98
Source Connector 오류 - 인프런 | 질문 & 답변
- 학습 관련 질문을 남겨주세요. 상세히 작성하면 더 좋아요!- 먼저 유사한 질문이 있었는지 검색해보세요.- 서로 예의를 지키며 존중하는 문화를 만들어가요.- 잠깐! 인프런 서비스 운영 관련 문
www.inflearn.com
- POST 메소드로 Topic 등록을 할 수 있고, GET 요청으로 조회, DELETE 요청으로 삭제 등을 할 수 있다.
https://velog.io/@anjinwoong/Kafka-Connect-%EC%9E%90%EC%A3%BC-%EC%82%AC%EC%9A%A9%ED%95%98%EB%8A%94-%EB%AA%85%EB%A0%B9%EC%96%B4API-%EC%A0%95%EB%A6%AC
[Kafka Connect] Connector Rest API 정리
Kafka Connect Rest API
velog.io
이제 Topic 이 만들어졌어야 할 것 같지만,,, 실제 명령어로 확인해보면 만들어지지 않았다. 변경점이 있어야 Connector 가 Topic을 자동으로 만들어준다.
변경점을 만들어보자. 데이터베이스에 다음과 같은 데이터를 SQL로 삽입한다.
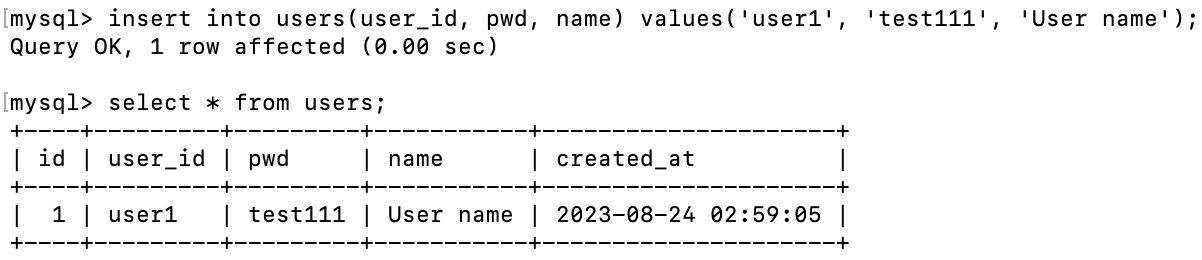
이러면 다음과 같이 Topic이 만들어졌다.

이 토픽의 Consumer를 만들어 테스트해보자. 비록 목표는 Consumer가 아니라 Connect이지만 테스트하는 것!

아까와 같은 Consumer 명령어를 입력했더니, 데이터베이스 입력에 대한 JSON 파일이 나온다.
실제로 테이블의 정보들이 고스란히 들어있어, 데이터를 전달 받은 쪽에서 똑같은 데이터를 데이터베이스에 넣을 수 있도록 되어 있다.
이제 Consumer 가 아니라. Sink Connect를 이용해 실제 변경된 데이터베이스를 동기화하는 작업을 해보자.
Kafka Sink Connect 사용
Kafka Sink Connect를 추가할 때도 마찬가지로 Postman을 이용하려 한다. 다음과 같이 요청하자.
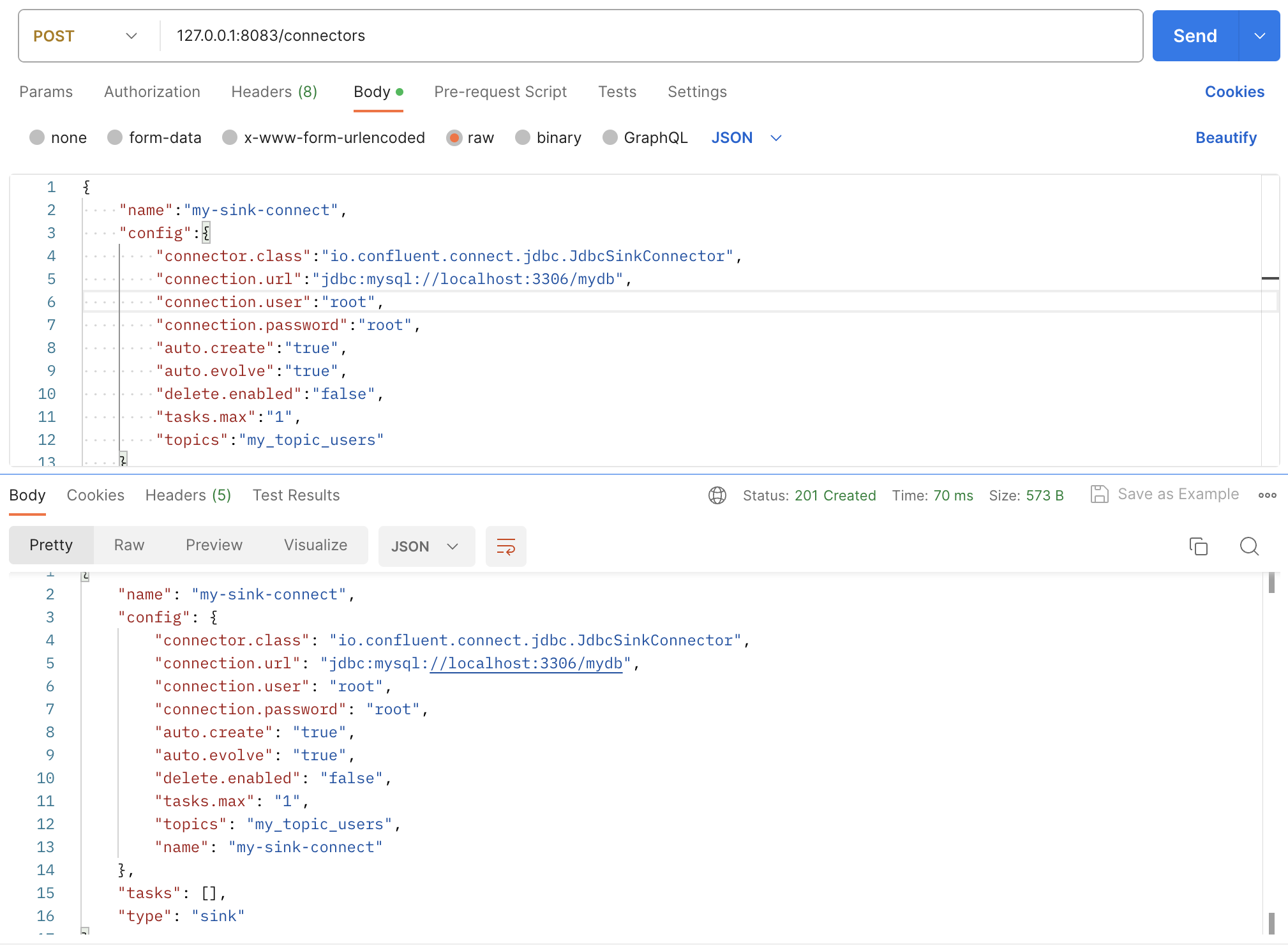
- auto.create 설정이 되어 있어 Topic의 이름과 같은 테이블이 자동으로 생성되게 한다.
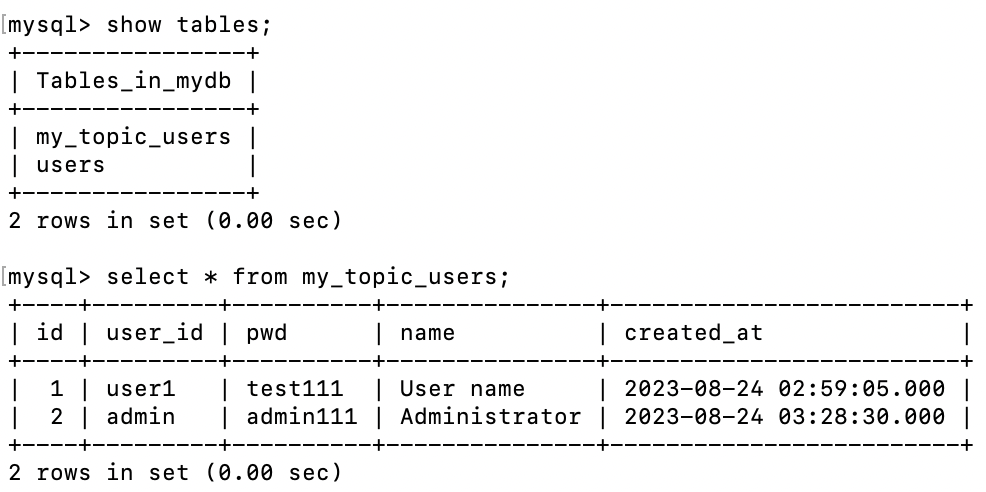
테이블이 새로 생성되고, users 테이블에 있던 정보가 새로 생성된 테이블에 적용된 것을 볼 수 있다.
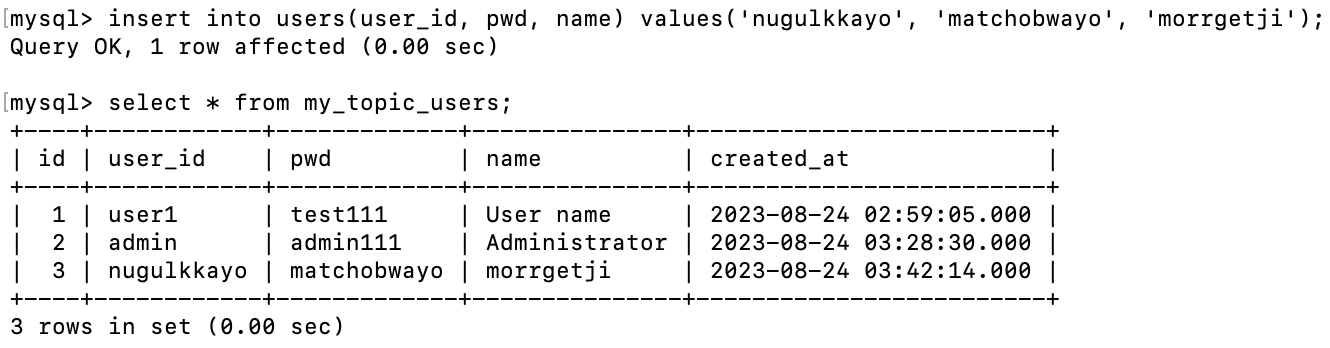
Users 테이블에 데이터를 삽입해도, 다른 테이블에 데이터가 동기화되는 것을 볼 수 있다.
궁극적인 목표는 마무리했다. 근데 실험을 하나 더 해보자. 직전에 Consumer로 테스트 했을 때, JSON 형식으로 데이터를 잘 삽입할 수 있도록 가공되어 주어진다고 했다. 이 걸 Producer 입장에서 그대로 Sink Connector 가 연결된 Topic 에 던진다면 어떻게 될까...?
바로 가보쟈
우선 맨 처음에 했던 대로 console producer를 my_topic_users에 대해 실행하자. 그 후 다음과 같은 메시지를 보낼 것이다.
{"schema":{"type":"struct","fields":[{"type":"int32","optional":false,"field":"id"},{"type":"string","optional":true,"field":"user_id"},{"type":"string","optional":true,"field":"pwd"},{"type":"string","optional":true,"field":"name"},{"type":"int64","optional":true,"name":"org.apache.kafka.connect.data.Timestamp","version":1,"field":"created_at"}],"optional":false,"name":"users"},"payload":{"id":4,"user_id":"matchirago","pwd":"nada","name":"naya","created_at":1692848634000}}자세하게 무슨 의미인지는 볼 필요 없다. 아까 전에 Consumer 테스트 때 나온 것을 뒤에 payload 부분만 살짝 변형했다. 즉 새로운 데이터라는 것이다. 이걸 console 에 직접 입력한다면, 마치 users 테이블에 데이터가 삽입된 것처럼 행동해야 맞을 것이다.

4번 데이터가 방금 입력한 데이터이다.
'[MSA] Spring Cloud로 개발하는 마이크로서비스 애플리케이션' 카테고리의 다른 글
| 섹션 13 : Spring Cloud로 개발하는 마이크로서비스 애플리케이션(MSA) (0) | 2023.09.05 |
|---|---|
| 섹션 12 : Spring Cloud로 개발하는 마이크로서비스 애플리케이션(MSA) (1) | 2023.09.02 |
| 섹션 10 : Spring Cloud로 개발하는 마이크로서비스 애플리케이션(MSA) (0) | 2023.08.18 |
| 섹션 9 : Spring Cloud로 개발하는 마이크로서비스 애플리케이션(MSA) (0) | 2023.08.11 |
| 섹션 8 : Spring Cloud로 개발하는 마이크로서비스 애플리케이션(MSA) (0) | 2023.08.11 |