시간 복잡도가 O(NlogN) 인 대표적인 3개의 알고리즘 (Quick / Merge / Heap) 을 알아보고, 정렬 알고리즘의 O(NlogN) 이라는 시간복잡도와 각 언어에서 어떤 정렬 알고리즘이 쓰이는 지 알아보자.
Quick Sort (퀵 정렬)

퀵 정렬은 다음과 같은 단계로 진행된다.
- pivot을 정한다.
- pivot 기준 왼쪽에는 모두 pivot 값보다 작은 값들을, pivot 기준 오른쪽에는 모두 pivot 값보다 큰 값들이 되게 한다.
- pivot 기준 왼쪽, 오른쪽 배열을 각각 다시 퀵 정렬한다.
다음과 같은 배열이 있다고 가정하자.
여기서 빨간 색인 4를 pivot으로 정했다고 하자. 위의 2단계를 거치고 나면 다음과 같이 변한다.
이제 왼쪽, 오른쪽 배열에서 다시 pivot을 정하고 정렬한다. 다음과 같은 순서로 정렬된다.
퀵 정렬의 장점
참조 지역성
퀵 정렬의 장점은 이름에서도 알 수 있듯이 빠르다는 것이다. 그 이유는 Locality와 관련되어 있다.
Locality, 지역성이란 참조할 "주변"의 데이터를 재참조할 확률이 높다는 것이다. "주변"은 시간적으로 주변 (최근에 참조한 데이터를 다시 참조), 공간적으로 주변 (참조한 근처의 데이터를 참조)이 있다.
퀵 정렬은 위의 정렬 시뮬레이션 gif 만 보더라도 재귀적으로 파고 들어가 좁은 구역에서 정렬을 마친 후 다른 구역으로 이동한다. 이 말은 지역성이 높다는 것이고, CPU Cache의 hit 가 많다는 것이다.
따라서 캐시의 히트율이 높아져 다른 정렬보다 훨씬 빠르다.
(단, 배열이 아닌, 실제 원소가 서로 이어져 있지 않은 Linked List의 경우 이 장점이 없어질 수 있다.)
퀵 정렬의 단점
이런 빠르다는 장점 뒤엔 많은 단점도 있다.
최악의 경우 O(N^2) 시간복잡도
기본적으로 이미 정렬되어 있거나, 반대로 정렬되어 있는 경우 모든 원소를 두 번씩 훑게 되어 O(N^2) 의 시간복잡도를 가진다.
하지만 이것은 pivot을 정할 때 맨 앞 혹은 맨 뒤의 원소를 pivot으로 정해서 일어나는 일이다. 즉, pivot을 정할 때 최댓값 혹은 최솟값으로 정하면 최악의 경우이다.
따라서 이를 피하기 위해 pivot을 랜덤으로 정하거나 배열의 중앙값으로 정하기도 한다. pivot을 랜덤으로 정하게 되면 최댓값 혹은 최솟값이 pivot으로 정해질 확률이 낮아진다.
하지만, 이러더라도 최악의 경우 O(N^2) 이 나올 확률이 있다는 것은 굉장한 단점이다. 이걸 피하기 위해 pivot을 두개 정하거나, 파티션을 3개로 하거나, 여러 알고리즘을 섞기도 한다. 각종 언어에서는 이렇게 복잡하게 최적화된 알고리즘을 라이브러리로 제공한다.
불안정 (Unstable Sort)
원소들 중에 같은 값이 있는 경우 같은 값들의 정렬 이후 순서가 초기 순서와 달라질 수 있는 것을 불안정하다고 한다.
예를 들어 3,1,2,4,3 을 정렬하면 1,2,3,3,4 가 된다. 이 때, 3이라는 두 숫자의 순서가 달라질 수 있다는 것이다. 그냥 숫자라면 괜찮지만, 여러 데이터를 담는 객체이면 문제가 된다.
작은 크기 Dataset에서 빠름
큰 데이터에서 퀵 정렬은 안 좋을 수 있다. 재귀 함수를 기반으로 동작해서 호출 스택이 과도하게 쌓일 수 있다는 점, 최악의 경우를 피하기 위한 pivot을 랜덤으로 정하거나 중간값으로 정하는 등의 부가적인 동작이 큰 크기의 Dataset에서는 부담이기 때문이다.
Merge Sort (병합/합병 정렬)
합병 정렬은 다음 peudo code를 따른다.
원소가 하나가 될 때까지 파고 들어가, 합치면서 옳은 순서로 정렬하는 것이다. 이미지로 보면 다음과 같다.
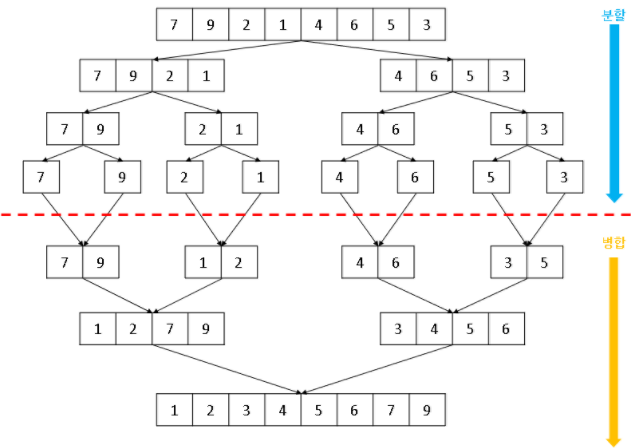
합병 정렬의 장점
퀵 정렬의 단점이랑 대치된다.
배열의 상태와 관계없이 항상 O(NlogN) 이다.
퀵 정렬과 다르게 입력 데이터의 상태와 관계 없이 항상 O(NlogN)을 유지한다.
안정 (Stable Sort)
퀵 정렬과 다르게 Stable 하다. 원소들 중에 같은 값이 있는 경우 같은 값들의 정렬 이후 순서가 초기 순서와 같다는 것이다.
예를 들어 3,1,2,4,3 을 정렬하면 1,2,3,3,4 가 된다. 이 때, 3이라는 두 숫자의 순서가 같다는 것이다.
병렬 처리 용이
나누어진 각각의 함수에게 다른 쓰레드를 주어 병렬로 처리하면 실행 속도에 도움이 된다. 이 방법을 Parallel Merge Sort라 한다. 자세한 내용은 다음을 참고하자. https://junstar92.tistory.com/268
Parallel Merge Sort (merge operation)
References Programming Massively Parallel Processors Contents A Sequential Merge Algorithm A Parallelization Approach : co-rank CO-RANK function Implementation A Basic Parallel Merge Kernel A Tiled Merge Kernel A Circular-Buffer Merge Kernel 이번 포스
junstar92.tistory.com
연결 리스트 정렬
퀵 정렬의 장점이 지역성이라고 했다. 하지만 연결 리스트는 실제 데이터가 물리적으로 근처에 있지 않아 캐시 히트율이 떨어질 수 있다. 이런 경우엔 퀵 정렬보다 합병 정렬을 사용하는 것이 좋다.
합병 정렬의 단점
추가적인 메모리 필요
위의 Pesudo Code 에서 merge() 함수를 할 때, 즉 배열을 합칠 때 합칠 다른 공간이 필요하다. 마지막에 합칠 때는 데이터만큼의 공간이 그대로 필요하다. 즉, 메모리가 제한적인 상황에서는 조심해야 한다는 것이다.
Heap Sort (힙 정렬)
최대 힙 트리나 최소 힙 트리를 구성해 정렬을 하는 방법으로서, 내림차순 정렬을 위해서는 최소 힙을 구성하고 오름차순 정렬을 위해서는 최대 힙을 구성하면 된다.
사실상 알고리즘 자체는 선택 정렬과 거의 유사하다. 최솟값/최댓값을 찾아 맨 앞에 놓고 반복하는 것을 직접하는 선택 정렬과 달리, 힙 정렬은 힙에 데이터를 삽입하는 것으로 끝나는 것이다.
힙 정렬의 장점
배열의 상태와 관계없이 항상 O(NlogN) 이다.
퀵 정렬과 다르게 입력 데이터의 상태와 관계 없이 항상 O(NlogN)을 유지한다.
힙 정렬의 단점
다음 두 단점은 퀵 정렬과 합병 정렬의 핵심적인 장점에 대치된다.
지역성 낮음
힙 정렬은 힙의 특성상 부모 노드와 자식 노드 간의 거리가 멀어질수록 메모리 상에서 떨어진 위치에 있을 확률이 높다. 자료 구조의 특성상 물리적인 지역성이 떨어져 캐시의 히트율이 낮다. 따라서 (특히 데이터의 크기가 작을 때) 퀵 정렬이 빠를 가능성이 높다.
특히, 합병 정렬보다 지역성이 낮다.
불안정 (Unstable Sort)
단순히 힙에 데이터를 삽입하고 제거하는 과정만 생각해봐도 기존 데이터의 순서와는 뒤죽박죽이 될 것임을 생각할 수 있다. 합병 정렬과는 달리 불안정한 정렬이다.
왜 O(NlogN) ?
정렬 알고리즘은 유독 O(NlogN) 인 경우가 많다. 비교 기반의 알고리즘은 O(NlogN) 보다 좋을 수 없다는 것이 이미 증명되어 있다.
다음 사진의 트리를 보자. Comparison Tree이다.
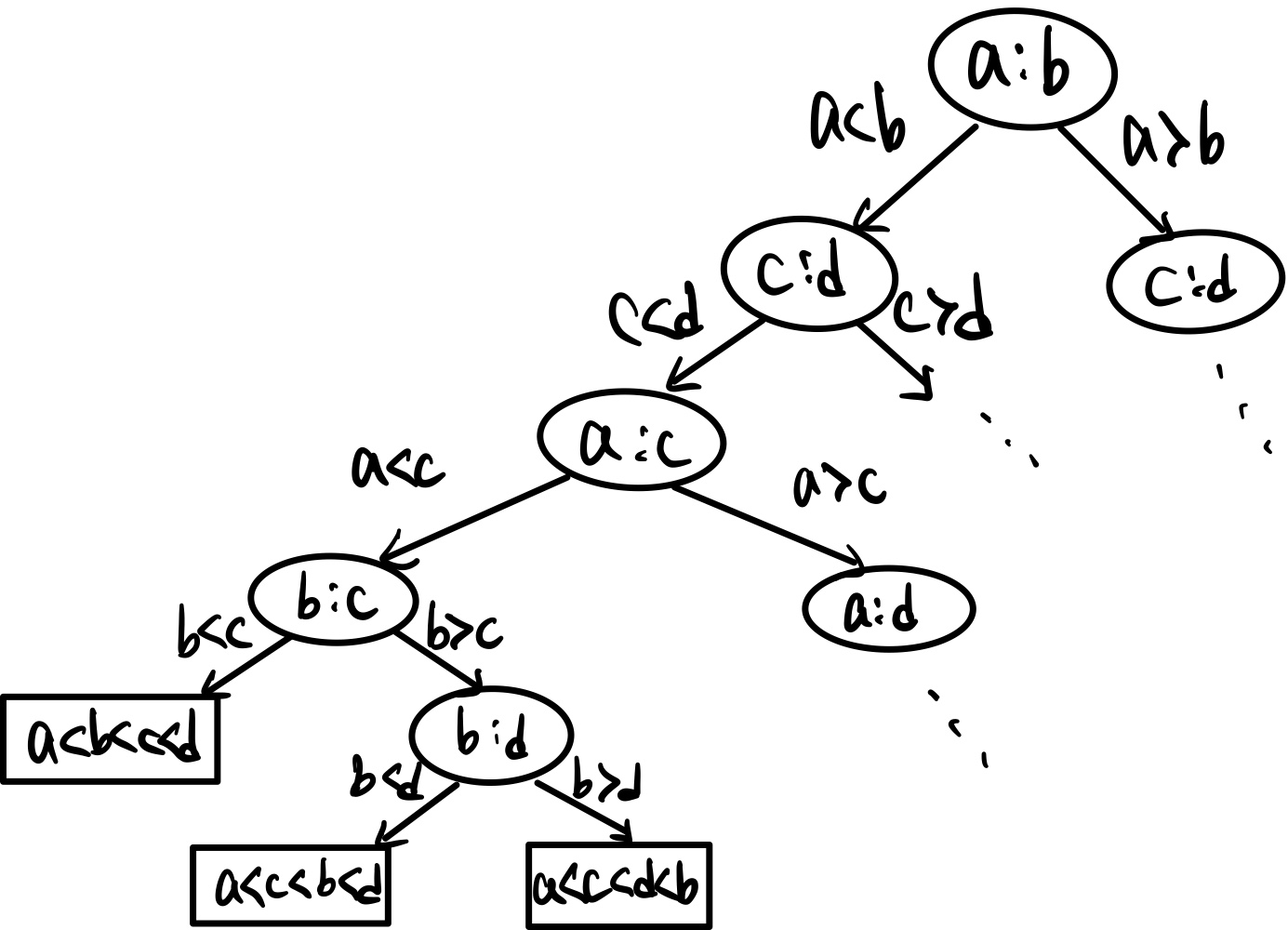
비교를 할 때, 이와 같은 트리로 모든 경우를 설명할 수 있다.
루트 노드에서 a와 b를 비교해 두 자식 중 하나로 내려간다. 이를 계속 반복하면 리프 노드에 도달하는데, 이 하나하나의 경우가 비교를 다 한 것이다.
그렇다면 이 트리의 높이가 비교 기반 정렬의 시간 복잡도라고 할 수 있겠다! 트리의 높이를 알아보자.
우선 리프 노드의 개수는 n! 개이다. 위의 경우는 n=4이므로 리프 노드가 24개가 생긴다.
이진 트리에서 N개의 리프 노드를 가질 때 높이는 lg(N) 이므로 이 트리의 높이는 lg(n!) 보다 크거나 같다.(단, lg는 이진 로그)
트리의 높이 >= lg(n!)
이 때, 충분히 큰 n에 대해 다음의 식이 성립하는 것을 stirling's fomula 라 한다.

따라서 다음이 성립한다.

따라서 다음과 같은 결론을 얻는다.
트리의 높이 >= θ(nlgn)
트리의 높이 = Ω(nlgn)
따라서 트리의 높이인 비교 횟수는 NlogN 보다 크거나 같다. 즉, O(NlogN) 보다 좋은 비교 기반 정렬 알고리즘은 존재할 수 없다.
각 언어에서 어떤 알고리즘을 쓸까?
C++
<algorithm>
algorithm 헤더에 있는 sort 함수는, 예전엔 퀵 정렬을 사용했지만, 현재는 인트로 정렬이라는 하이브리드 정렬을 사용한다.
위키피디아에서 다음과 같이 소개한다.
Quicksort 로 시작하여 재귀 깊이가 정렬되는 요소 수를 기반으로 한 수준( 로그 )을 초과하면 힙 정렬 로 전환 하고 요소 수가 특정 임계값 미만이면 삽입 정렬 로 전환합니다.

기본적으로 퀵 정렬이다. 단, 퀵 정렬 중 분할된 부분 배열이 굉장히 작아지면 삽입정렬로 전환한다.
왜일까?? 삽입정렬은 구현이 간단하고 참조 지역성이 좋기 때문이다.
참고
삽입 정렬은 완전 역순일 경우 O(N^2)이 걸린다. 단, 참조 지역성이 좋기 때문에 O(N^2) 임에도 굉장히 빠르게 동작한다. 또한 현실의 데이터는 어느 정도 정렬되어 있는 경우가 많은데 이 때 좋은 간단한 알고리즘이 삽입 정렬이다.https://d2.naver.com/helloworld/0315536
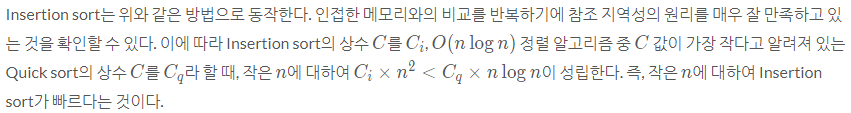
또한 maxdepth는 호출 스택의 깊이인데, 초기에 설정된 어떤 값을 모두 사용했는데도 정렬되지 않으면 배열이 너무 크기 때문에 힙 정렬을 사용한다.
STL::list::sort()
합병 정렬을 사용한다.
왜?!
위에서 공부한 내용들을 바탕으로 하면 쉽게 이해할 수 있다. <algorithm>의 sort()는 배열, 즉 물리적으로 가까이 있는 데이터들이므로 지역성이 높을 수록 장점이 있는 퀵 정렬을 사용한 것이고, 이 장점을 살리지 못하는 list::sort()는 합병 정렬을 사용하는 것이다.
Java
Arrays.sort()
실제 라이브러리를 타고 들어가면 다음과 같이 나온다.
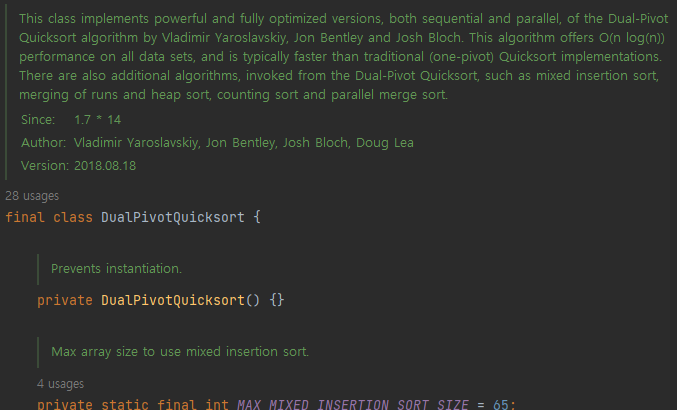
pivot을 두 개 정하고, 파티션을 3개 사용하는 DualPivotQuicksort 이다. 하지만 선택 정렬, 합병 정렬, 힙 정렬, 계수 정렬, 병렬 합병 정렬 을 추가로 호출할 수 있다고 한다.
Collections.sort()

이 구현체는 Tim Peters의 Python용 리스트 정렬(TimSort)에서 수정되었습니다. 그것은 Peter McIlroy의 "Optimistic Sorting and Information Theoretic Complexity"에서 사용된 기법을 활용합니다.
파이썬에서 사용할 목적으로 만들어진 TimSort를 사용한다. TimSort는 합병 정렬과 선택 정렬을 합한 방법이다. 클 때는 합병 정렬, 작아진 부분 배열에 대해 선택 정렬을 하는 것이다.
왜?!
위에서 공부한 내용들을 바탕으로 하면 쉽게 이해할 수 있다. Arrays.sort() 는 배열, 즉 물리적으로 가까이 있는 데이터들이므로 지역성이 높을 수록 장점이 있는 퀵 정렬을 사용한 것이고, 이 장점을 살리지 못하는 Collections.sort()는 합병 정렬 기반의 Tim Sort를 사용하는 것이다.
Python
https://d2.naver.com/helloworld/0315536
자세한 내용은 위 글을 읽어보자. 위에 말한 대로 클 때는 합병 정렬, 작아진 부분 배열에 대해 선택 정렬을 하는 것이다. 이에 더해 Run을 단위로 하는 등 여러 최적화 기법이 들어갔다.
현재 2.3 이후 버전의 Python, Java SE 7, Android, Google chrome (V8), 그리고 swift까지 많은 프로그래밍 언어에서 표준 정렬 알고리즘으로 채택되어 사용되고 있다.
V8 엔진을 사용하는 Java Script 도 Tim Sort를 사용하고 있다.
Reference
https://www.toptal.com/developers/sorting-algorithms
https://hongjw1938.tistory.com/192
https://ko.wikipedia.org/wiki/%ED%80%B5_%EC%A0%95%EB%A0%AC