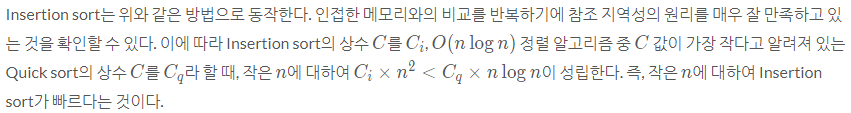퀵 정렬의 장점이 지역성이라고 했다. 하지만 연결 리스트는 실제 데이터가 물리적으로 근처에 있지 않아 캐시 히트율이 떨어질 수 있다. 이런 경우엔 퀵 정렬보다 합병 정렬을 사용하는 것이 좋다.
합병 정렬의 단점
추가적인 메모리 필요
위의 Pesudo Code 에서 merge() 함수를 할 때, 즉 배열을 합칠 때 합칠 다른 공간이 필요하다. 마지막에 합칠 때는 데이터만큼의 공간이 그대로 필요하다. 즉, 메모리가 제한적인 상황에서는 조심해야 한다는 것이다.
Heap Sort (힙 정렬)
최대 힙트리나 최소 힙 트리를 구성해 정렬을 하는 방법으로서, 내림차순 정렬을 위해서는 최소 힙을 구성하고 오름차순 정렬을 위해서는 최대 힙을 구성하면 된다.
사실상 알고리즘 자체는 선택 정렬과 거의 유사하다. 최솟값/최댓값을 찾아 맨 앞에 놓고 반복하는 것을 직접하는 선택 정렬과 달리, 힙 정렬은 힙에 데이터를 삽입하는 것으로 끝나는 것이다.
힙 정렬의 장점
배열의 상태와 관계없이 항상 O(NlogN) 이다.
퀵 정렬과 다르게 입력 데이터의 상태와 관계 없이 항상 O(NlogN)을 유지한다.
힙 정렬의 단점
다음 두 단점은 퀵 정렬과 합병 정렬의 핵심적인 장점에 대치된다.
지역성 낮음
힙 정렬은 힙의 특성상 부모 노드와 자식 노드 간의 거리가 멀어질수록 메모리 상에서 떨어진 위치에 있을 확률이 높다. 자료 구조의 특성상 물리적인 지역성이 떨어져 캐시의 히트율이 낮다. 따라서 (특히 데이터의 크기가 작을 때) 퀵 정렬이 빠를 가능성이 높다.
특히, 합병 정렬보다 지역성이 낮다.
불안정 (Unstable Sort)
단순히 힙에 데이터를 삽입하고 제거하는 과정만 생각해봐도 기존 데이터의 순서와는 뒤죽박죽이 될 것임을 생각할 수 있다. 합병 정렬과는 달리 불안정한 정렬이다.
왜 O(NlogN) ?
정렬 알고리즘은 유독 O(NlogN) 인 경우가 많다. 비교 기반의 알고리즘은 O(NlogN) 보다 좋을 수 없다는 것이 이미 증명되어 있다.
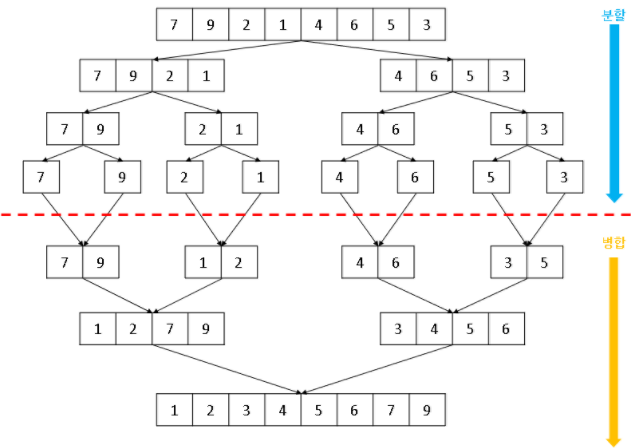
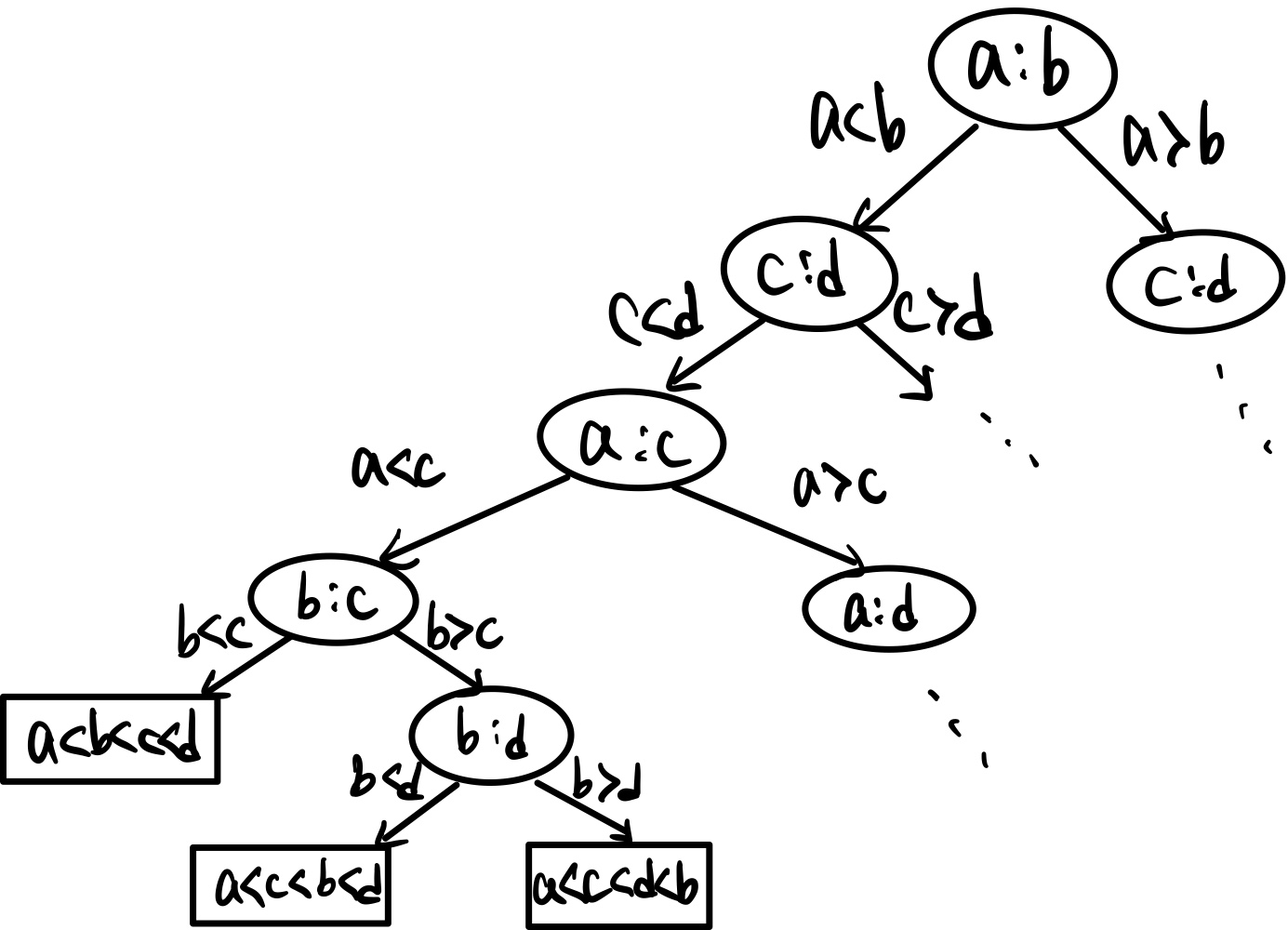
다음 사진의 트리를 보자. Comparison Tree이다.
비교를 할 때, 이와 같은 트리로 모든 경우를 설명할 수 있다.
루트 노드에서 a와 b를 비교해 두 자식 중 하나로 내려간다. 이를 계속 반복하면 리프 노드에 도달하는데, 이 하나하나의 경우가 비교를 다 한 것이다.
그렇다면 이 트리의 높이가 비교 기반 정렬의 시간 복잡도라고 할 수 있겠다! 트리의 높이를 알아보자.
우선 리프 노드의 개수는 n! 개이다. 위의 경우는 n=4이므로 리프 노드가 24개가 생긴다.
이진 트리에서 N개의 리프 노드를 가질 때 높이는 lg(N) 이므로 이 트리의 높이는 lg(n!) 보다 크거나 같다.(단, lg는 이진 로그)
트리의 높이 >= lg(n!)
이 때, 충분히 큰 n에 대해 다음의 식이 성립하는 것을 stirling's fomula 라 한다.
Stirling's Fomula
따라서 다음이 성립한다.
따라서 다음과 같은 결론을 얻는다.
트리의 높이 >= θ(nlgn) 트리의 높이 = Ω(nlgn)
따라서 트리의 높이인 비교 횟수는 NlogN 보다 크거나 같다. 즉, O(NlogN) 보다 좋은 비교 기반 정렬 알고리즘은 존재할 수 없다.
각 언어에서 어떤 알고리즘을 쓸까?
C++
<algorithm>
algorithm 헤더에 있는 sort 함수는, 예전엔 퀵 정렬을 사용했지만, 현재는 인트로 정렬이라는 하이브리드 정렬을 사용한다.
위키피디아에서 다음과 같이 소개한다.
Quicksort 로 시작하여 재귀 깊이가 정렬되는 요소 수를 기반으로 한 수준( 로그 )을 초과하면 힙 정렬 로 전환 하고 요소 수가 특정 임계값 미만이면 삽입 정렬 로 전환합니다.
https://en.wikipedia.org/wiki/Introsort
기본적으로 퀵 정렬이다. 단, 퀵 정렬 중 분할된 부분 배열이 굉장히 작아지면 삽입정렬로 전환한다.
왜일까?? 삽입정렬은 구현이 간단하고 참조 지역성이 좋기 때문이다.
참고 삽입 정렬은 완전 역순일 경우 O(N^2)이 걸린다. 단, 참조 지역성이 좋기 때문에 O(N^2) 임에도 굉장히 빠르게 동작한다. 또한 현실의 데이터는 어느 정도 정렬되어 있는 경우가 많은데 이 때 좋은 간단한 알고리즘이 삽입 정렬이다.https://d2.naver.com/helloworld/0315536
또한 maxdepth는 호출 스택의 깊이인데, 초기에 설정된 어떤 값을 모두 사용했는데도 정렬되지 않으면 배열이 너무 크기 때문에 힙 정렬을 사용한다.
위에서 공부한 내용들을 바탕으로 하면 쉽게 이해할 수 있다. <algorithm>의 sort()는 배열, 즉 물리적으로 가까이 있는 데이터들이므로 지역성이 높을 수록 장점이 있는 퀵 정렬을 사용한 것이고, 이 장점을 살리지 못하는 list::sort()는 합병 정렬을 사용하는 것이다.
Java
Arrays.sort()
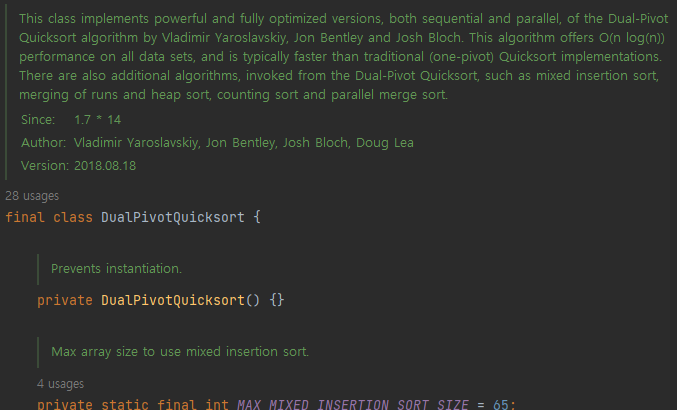
실제 라이브러리를 타고 들어가면 다음과 같이 나온다.
pivot을 두 개 정하고, 파티션을 3개 사용하는 DualPivotQuicksort 이다. 하지만 선택 정렬, 합병 정렬, 힙 정렬, 계수 정렬, 병렬 합병 정렬 을 추가로 호출할 수 있다고 한다.
Collections.sort()
이 구현체는 Tim Peters의 Python용 리스트 정렬(TimSort)에서 수정되었습니다. 그것은 Peter McIlroy의 "Optimistic Sorting and Information Theoretic Complexity"에서 사용된 기법을 활용합니다.
파이썬에서 사용할 목적으로 만들어진 TimSort를 사용한다. TimSort는 합병 정렬과 선택 정렬을 합한 방법이다. 클 때는 합병 정렬, 작아진 부분 배열에 대해 선택 정렬을 하는 것이다.
왜?!
위에서 공부한 내용들을 바탕으로 하면 쉽게 이해할 수 있다. Arrays.sort() 는 배열, 즉 물리적으로 가까이 있는 데이터들이므로 지역성이 높을 수록 장점이 있는 퀵 정렬을 사용한 것이고, 이 장점을 살리지 못하는 Collections.sort()는 합병 정렬 기반의 Tim Sort를 사용하는 것이다.